
简介
本文主要介绍如何通过tesseract进行文字识别,及其识别效果。
效果图
| 图片 | |
|---|---|
| 测试图 |  |
| 测试结果 | 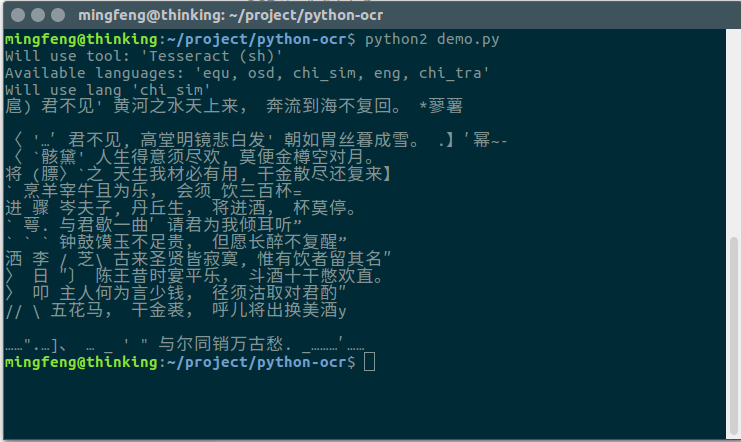 |
环境
- ubuntu
- python2.7
安装
- tesseract
sudo apt-get install tesseract-ocr
- 安装tesseract tessdata
https://github.com/tesseract-ocr/tessdata 下载对应语言文字学习数据,并保存到/usr/share/tesseract-ocr/tessdata或/usr/share/tessdata位置 -
pyocr
sudo pip install pyocr
测试代码
- demo.py
from PIL import Image
import sys
import pyocr
import pyocr.builders
import sys
tools = pyocr.get_available_tools()
if len(tools) == 0:
print("Not found OCR tool")
sys.exit(1)
tool = tools[0]
print("Will use tool: '%s'" % (tool.get_name()))
langs = tool.get_available_languages()
print("Available languages: '%s'" % ", ".join(langs))
print("Will use lang '%s'" % ("chi_sim"))
txt = tool.image_to_string(
Image.open('images/jjj.jpg'),
lang='chi_sim',
builder=pyocr.builders.TextBuilder(tesseract_layout=6)
)
print(txt)
运行
python2 demo.py
评价
文字识别的精度有待提升。一些像素低的,如标点符号都不能很好的解析出来。有兴趣的同学可以深入研究一下。
本文涉及代码
https://github.com/cangyan/python-ocr